Journey to DataDevOps
data-science devops 19-01-2025
Try out Practical implementation of dataops with this notebook
Introduction
DataDevOps, also known as DataOps, is essentially the application of DevOps practices to the field of data science. As organizations increasingly rely on data-driven insights for strategic decision-making, the need to deliver data-driven applications efficiently and reliably has never been greater. In this blog, we will explore how integrating DevOps practices into data science workflows can enhance the speed and quality of data-driven application delivery. We’ll delve into the principles, benefits, and key components of DataDevOps, and provide insights into how you can embark on this transformative journey.
Understanding DataDevOps
What is DataDevOps?
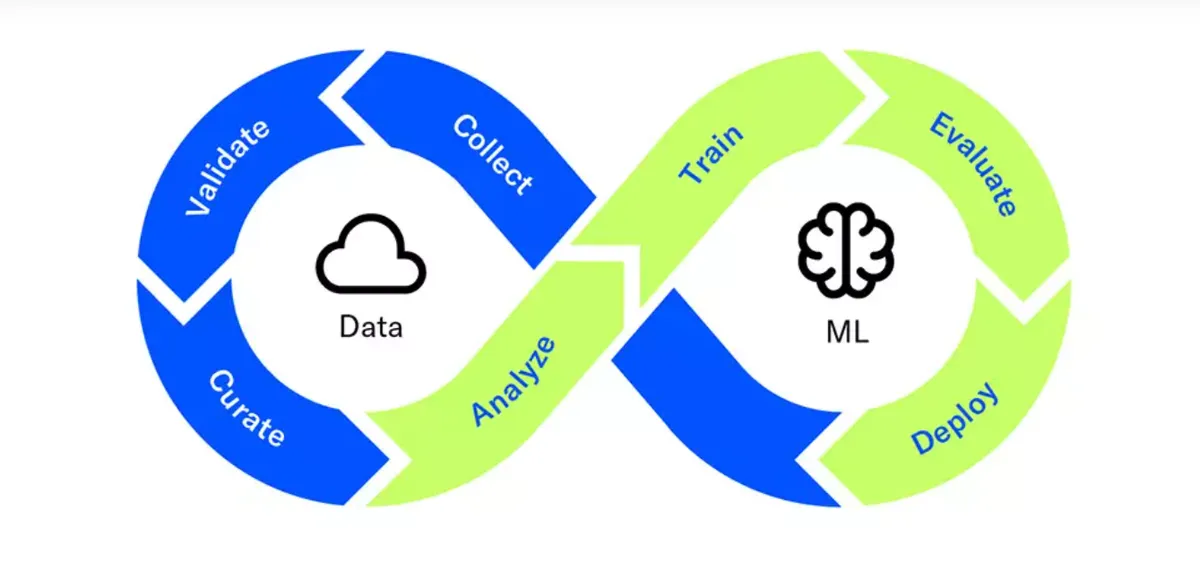
DataDevOps merges the principles of DevOps with data engineering and data science. Traditional DevOps focuses on automating and streamlining software development and deployment processes. DataDevOps extends these principles to the data lifecycle, including data collection, processing, analysis, and deployment of data models. The goal is to create a seamless, automated, and efficient pipeline for delivering data-driven solutions.
Key Principles of DataDevOps
- Collaboration: Just like in DevOps, DataDevOps emphasizes collaboration between data engineers, data scientists, and operations teams. This ensures that all stakeholders are aligned and can work together effectively.
- Automation: Automating repetitive and time-consuming tasks, such as data cleaning, model training, and deployment, helps reduce errors and accelerates the development cycle.
- Continuous Integration and Continuous Deployment (CI/CD): Implementing CI/CD pipelines for data ensures that changes are tested and deployed quickly and reliably.
- Monitoring and Feedback: Continuous monitoring of data processes and models in production helps in quickly identifying and addressing issues, ensuring the reliability and performance of data applications.
Benefits of Adopting DataDevOps
- Increased Efficiency: Automation of data workflows reduces manual effort, allowing data teams to focus on more strategic tasks.
- Faster Time-to-Market: Streamlined processes and CI/CD pipelines enable faster deployment of data models and applications, giving organizations a competitive edge.
- Improved Quality: Automated testing and monitoring ensure that data models are robust and perform well in production environments.
- Scalability: DataDevOps practices help organizations scale their data operations effectively, handling larger volumes of data and more complex workflows with ease.
- Better Collaboration: Enhanced collaboration between data and operations teams leads to more innovative solutions and a cohesive working environment.
Key Components of a DataDevOps Framework
Data Ingestion and Processing
- Data Pipelines: Automate the process of collecting, processing, and transforming raw data into usable formats.
- ETL Tools: Utilize Extract, Transform, Load (ETL) tools to streamline data integration from various sources.
Model Development and Deployment
- Version Control: Use version control systems (e.g., Git) to manage changes to data and models.
- CI/CD Pipelines: Implement CI/CD pipelines for continuous testing, integration, and deployment of data models.
Monitoring and Maintenance
- Monitoring Tools: Deploy monitoring tools to track the performance and accuracy of data models in production.
- Feedback Loops: Establish feedback loops to gather insights from production data, helping to refine and improve models continuously.
Implementing DataDevOps in Your Organization
Steps to Get Started
- Assess Current Workflows: Evaluate your existing data workflows to identify bottlenecks and areas for improvement.
- Build a Collaborative Team: Foster collaboration between data engineers, data scientists, and operations teams.
- Adopt Automation Tools: Implement tools for automating data ingestion, processing, model training, and deployment.
- Develop CI/CD Pipelines: Establish CI/CD pipelines to ensure continuous integration and deployment of data models.
- Monitor and Iterate: Continuously monitor data processes and models, and iterate based on feedback and performance metrics.
Challenges and Considerations
- Cultural Shift: Moving to a DataDevOps approach requires a cultural shift towards collaboration and automation.
- Tool Integration: Integrating various tools and platforms can be challenging, but it’s crucial for a seamless workflow.
- Skill Development: Training and upskilling team members in DevOps and automation practices is essential for successful implementation.
Conclusion
The journey to DataDevOps is a transformative one, promising increased efficiency, faster time-to-market, and improved quality of data-driven applications. By adopting DevOps principles and practices, organizations can build robust, scalable, and high-performing data pipelines and models. As data continues to play a pivotal role in business decision-making, embracing DataDevOps will be key to staying competitive and driving innovation. Start your DataDevOps journey today and unlock the full potential of your data-driven initiatives.



